Tihti pöördutakse meie poole murega, et koduleht on aja jooksul aeglaseks muutunud. Kuigi selliseid sümptomeid võivad põhjustada mitmed erinevad asjad, näiteks miljoni spämmikommentaari lisamine spämmerite poolt – kui kodulehel on kommentaaride kuvamine välja lülitatud, siis ei ole neid kommentaare küll näha, kuid koormust tekitavad ikka. Reeglina on siiski põhipõhjuseks ning ka esimeseks asjaks, mida üldse vaadata, andmebaasi indeksid. Kodulehe sisu on aja jooksul kasvanud, andmebaasi mootoril on tulemusi aina raskem üles leida ja see avaldubki aeglase lehelaadimisena. Appi tuleb andmebaasi indeks.
Mis on üldse andmebaasi indeks?
Lühidalt on indeksid mingitest andmetest tuletatud meta-andmed, mis aitavad neid andmeid hiljem üles leida. Lihtsaimal juhul võib võrdluseks kujutleda raamatute lõpus leiduvat märksõnade indeksit. Selle asemel, et mingi kindla märksõna leidmiseks lugeda läbi terve raamat, otsime soovitud sõna üles kõigepealt indeksist ja saame teada leheküljed, kus see sõna esineb. Mõne lehe läbivaatamine on tunduvalt lihtsam, kui terve raamatu ja seega leiame soovitu kiirelt üles. Kui meil raamatu lõpus seda märksõnade indeksit ei ole, siis ei jäägi muud üle, kui hakata tervet raamatut läbi lappama.
Andmebaasi indeksid on sisuliselt samasugused. Võibolla peamiseks erinevuseks on küll, et andmebaasi indekseid on palju rohkem. Raamatu märksõnad kehtivad terve raamatu jaoks, aga andmebaasi indeksid kehtivad kindla andmevälja (või väljade kohta), seega kui meie tabelis on välju mitmeid, siis peaks andmebaasis olema ka eraldi indeks iga välja kohta, mille järgi tahame teha otsingut või mille väärtusi soovime sorteerida.
Kuigi indeksid teevad andmebaasist andmete leidmise kiiremaks, siis liiga paljude indeksite kasutamine on ohuks andmebaasi jõudlusele, sest iga täiendav indeks tähendab täiendavat koormust andmete muutmisel. Kui meil indekseid üldse ei ole, siis tähendab kirje lisamine tabelisse vaid üht kirjutamistehet, mis ilmselgelt on väga kiire. Kui aga tabelile on määratud palju indekseid, tuleb lisaks andmete kirjutamisele hakata ka kõiki erinevaid indekseid ümber kirjutama. See on ka põhjus, miks andmebaasid ise kõike automaatselt ei indekseeri, selline lausindekseerimine mõjuks andmebaasi kirjutusjõudlusele täiesti laastavalt.
Kuna andmebaas ei saa kuidagi ette teada, et milliseid päringuid me sealt tegema hakkame, ei saa andmebaas ise neid indekseid ka ette ennustada. Seega on ajalooliselt nii jäänud, et andmebaasi kasutaja, kes ainsana teab, et milliseid päringuid ta baasist teha kavatseb, peab need indeksid ise looma.
Indekseerimise algoritmid
Kui me oleme määranud, et millistele väljadele indeksit rakendada ning samuti võibolla määranud minimaalse seadistuse (kas indeks on unikaalne või mitte, kas see koosneb ühest või mitmest väljast jne), siis hakkab andmebaas taustal indeksite kallal toimetama. Indeksid tuleb kuidagi koostada, need peab saama salvestada kettale ja mis peamine, neid peab saama kuidagi ka kiirelt lugeda.
Indekseerimise algoritme on erinevaid, sõltuvalt soovitud eesmärgist. Levinumateks indekseerimise algoritmideks oleks näiteks B-puu (B-tree), räsi (hash), R-tree, bitmap jmt. Andmebaaside analüüsimootorid on täiesti võimelised ise õige algoritmi valima, seega reeglina me ise seda tegema ei pea või ei saagi.
Räsi
Kui erinevaid algoritme lähemalt vaadata, siis kõige lihtsam indeks oleks tõenäoliselt räsi tüüpi indeks, mis on peamiselt kasutusel igasugu võti-väärtus tüüpi baasides. Andmeid salvestades teeme indekseeritavast väärtusest räsi, mille alusel leiame räsitabeli aadressi, kuhu salvestame viite kirje juurde.
SELECT * FROM kliendid WHERE id = 331
- Arvutame väärtusest 331 räsi ja saame otsitavaks aadressiks 0x6da37dd3
- Räsitabeli asukohas 0x6da37dd3 leiame viite kirje juurde 0x12345678
- Andmete hoiustamise asukohas, aadressil 0x12345678 asub rida otsitava kirje andmetega
Selline indeks on muidugi väga tõhus, aga eeldab siiski täpset pihtasaamist, see tähendab, et ei saa kasutada osalist või vahemiku põhist otsingut. Efektiivse kasutuse jaoks peab räsitabel mahtuma operatiivmällu, muidu kaotab see oma kiiruse. Lisaks ei saa me neid tulemusi ka mõistlikul viisil sorteerida.
SSTable
Räsi tüüpi indeksi edasiarendus on SSTable (sorteeritud stringide tabel), kus võtmed ei ole sorteeritud mitte räsifunktsiooni alusel, vaid tähestiku järgi. Siin oleks võibolla parimaks analoogiks entsüklopeediate köited (SSTable kontekstis segmendid): me teame iga köite esimest ja viimast sõna, seega kuigi me ei tea, et kus otsitav sõna täpselt asub, teame me, et millise köite indeksist seda edasi otsida. Me peame küll tegema ühe operatsiooni asemel mitu (kõigepealt leiame segmendi indeksi ja sealt seest siis juba õige võtme), aga SSTable lahendab ära nii osalise vaste (eelkõige küll sõna alguse järgi otsides), kui ka sorteerimise, pakkudes samas räsi-indeksile sarnast jõudlust. Lisaks ei ole selle puhul enam probleemi operatiivmäluga, kuna kogu indeksi asemel peame mälus hoidma ainul osa sellest ehk viiteid segmentide alguse ja lõpu indeksite juurde. Sellist indeksit kasutavad näiteks Cassandra, Google BigTable ja LevelDB perekonna andmebaasid nagu RocksDB.
B-tree
Kõige levinumaks indeksi algoritmiks on siiski B-puu ehk B-tree. Sarnaselt SSTable indeksile kasutame väärtuse leidmiseks vahemikke. B-tree juurikas on kirjas viited vahemike juurde, vahemike “okstel” on viited alamvahemike juurde jne. kuni viimaks leaf ehk lehekirjes viidatakse juba otsitava väärtuse juurde.
SELECT * FROM kliendid WHERE id = 331
| 0 | 100 | 200 | 300 | 400 | 500 |
V
| 300 | 320 | 340 | 360 | 380 |
V
| 320 | 325 | 330 | 335 |
V
| 330 | 331 | 332 | 333 | 334 |
V
(0x12345678, viide kirje asukoha juurde)
Muud olulised indeksid on veel mitmeveerulised indeksid (sinna alla lähevad ka mitmedimensionaalsed indeksid näiteks geograafiliste asukohtade leidmiseks) ning hägus-indeksid tekstiotsinguks.
Kui meil on nüüd mingi pilt ees, et mida indeksid tegelikult kujutavad, siis vaataks nende praktikas rakendamist.
Indeksite rakendamine praktikas
Põhiliselt kasutatavateks andmebaasideks Zone (ja ka muudes) veebiserverites on MySQL või MariaDB ning nende administreerimiseks on võimalik kasutada phpMyAdmin nimelist veebitarkvara. Kellele brauseripõhine tarkvara ei meeldi, saab kasutada ka mõnd allalaetavat töölaua rakendust, näiteks Mac OS puhul on üheks populaarsemaks selliseks administreerimisrakenduseks Sequel Pro. Töölauarakenduste puhul tuleb küll arvestada, et vaikimisi on tulemüüris andmebaasile ligipääs keelatud ja selle avamiseks tuleks teha Zone virtuaalserveri administreerimisliideses erand.
Suures plaanis on kõik sellised lahendused siiski sarnased ja seetõttu vaatame siin ainult phpMyAdmin veebiliidest.
Tabeli loomine
Andmebaasimootori valik
Kui me loome uut tabelit, avaneb meil järgmine vaade. Erilist tähelepanu tasuks pöörata all paremas nurgas olevale valikukastile “Storage Engine”, kus vaikimisi on valitud InnoDB.
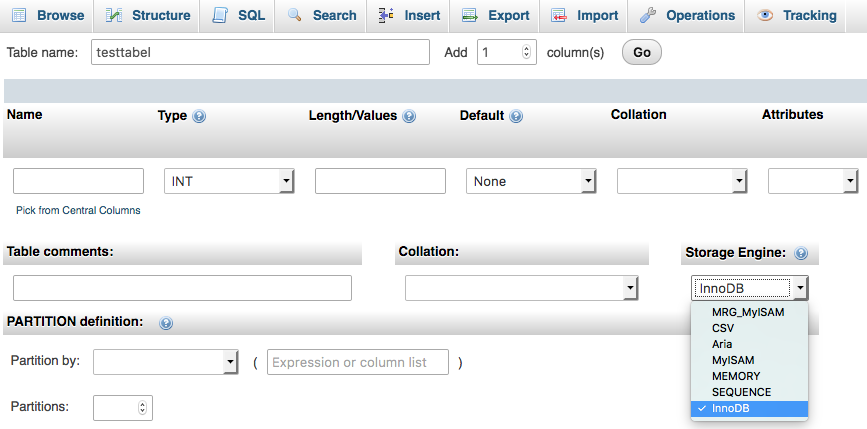
MySQL ja MariaDB ei ole suured monoliitsed tükid, vaid koosnevad ülemisest SQL kihist, millega suhtleb meie rakendus ning alumisest andmebaasikihist ehk andmebaasimootorist, mis tegeleb reaalse andmete majandamisega kettal. Eri tüüpi mootoritel on erinevad eesmärgid ja võimalused ning mootori tüübist sõltubki, millised indeksi tüübid meil üldse kasutada on.
Varasemalt oli eelistatud mootoriks MyISAM, kuid tänapäeval on selleks InnoDB. MyISAM on kergem ja seetõttu mõnes toimingus veidi kiirem, kuid samas ei taga see andmete terviklikkust ja seal ei ole võimalik teostada transaktsioone. Transaktsioon on siis selline toiming kus me seome mitu päringut kokku ja need peavad kas kõik õnnestuma või võetakse tehtud muudatused täielikult tagasi. Tüüpiliseks transaktsiooni näiteks on ülekanne kahe konto vahel. Esimese tehinguna võtame maksja kontolt summa maha ja teise tehinguna suurendame saaja kontol olevat summat. Kui nende kahe tehingu vahel peaks midagi juhtuma ja need toimingud ei ole teostatud transaktsiooniliselt, siis jääb maksja rahast ilma, aga saajani see kunagi ei jõua. Transaktsiooni korral võetakse probleemide ilmnemise korral kõik toimingud tagasi ja raha kontolt maha ei lähe.
InnoDB on igatahes hea valik ja seega võib selle vaikimisi alati valida. Välja arvatud muidugi juhul, kui me spetsiaalselt just mingit muud kindlat mootorit kasutada ei taha.
Välja indeks
Järgmine oluline valik on iga välja puhul määrata sellele sobiv indeks. Või siis mitte määrata, kui me teame, et selle välja alusel me kunagi ühtegi päringut ei tee.
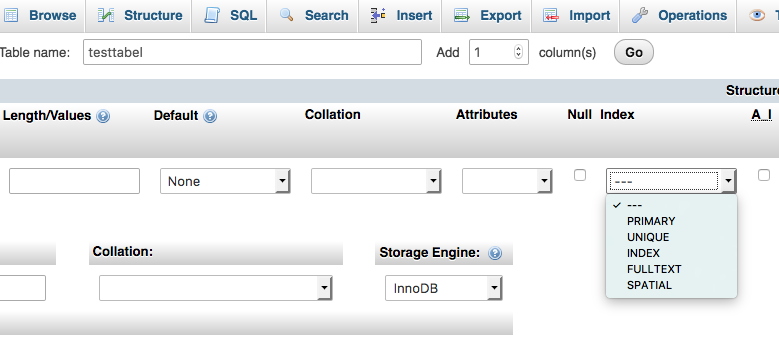
Kui kiirelt üle vaadata, siis on valikus järgmised variandid:
- PRIMARY ehk primaarvõti. See peaks igal tabelil olema määratud, kuna see saab olema iga kirje jaoks niiöelda kanooniline viide. Primaarvõtme kasutamine ei ole kohustuslik, aga selle mittekasutamine peaks olema selgelt põhjendatud. Tavaliselt käib primaarvõti INT tüüpi väljale koos A_I ehk AUTO_INCREMENT linnukesega. Sellisel juhul määratakse igale uuele kirjele primaarvõti automaatselt ja selleks on inkrementaalne number, kus esimese kirje primaarvõti on 1, järgmisel 2 jne. Primaarvõti võib olla ka igat muud tüüpi, näiteks VARCHAR või siis üldse üle mitme veeru, kuid tingimuseks on, et see väärtus peab olema iga kirje korral unikaalne.
- UNIQUE ehk sekundaarne unikaalne võti. Üsna sarnane PRIMARY tüüpi indeksile, kuna nõuab, et kirjes olev väärtus peab olema unikaalne ja üheski teises kirjes sama väärtust samal väljal olla ei tohi
- INDEX on niiöelda tavaline indeks, mis ei sea väärtustele piiranguid. Sama väärtust võib esineda erievates kirjetes
- FULLTEXT on hägus indeks tekstimassiivi seest tulemuste leidmiseks, sarnaselt siis otsingumootoritele, mis veebist märksõnade alusel dokumente leiavad. Kui tekstivälja INDEX leiab eelkõige täpseid või lähedasi vasteid või on kasutusel sorteerimise jaoks, siis FULLTEXT otsib tekstist märksõnu kasutades MATCH…AGAINST süntaksi. Suurema koormusega süsteemid tavaliselt seda indeksi kehva jõudluse tõttu ei kasuta, vaid indekseerivad tekstiotsingu sisendandmed mõnes spetsiaalselt märksõnade otsinguga tegelevas andmebaasis nagu näiteks ElasticSearch.
- SPATIAL on geograafiliste vahemike indekseerimiseks. Kui tavaline numbrivälja INDEX kasutab vaikimisi B-tree algoritmi, mis indekseerib ühemõõtmelise vahemiku, siis SPATIAL kasutab R-tree algoritmi, mis indekseerib kahemõõtmelise polügoni
Sõltuvalt andmebaasimootorist ning selle versioonist võib andmebaas lubada indeksi algoritmi ise valida. Siin näites on meil valida INT ehk numbritüüpi välja jaoks BTREE ja HASH vahel. Kui me algoritmi ise ei vali, siis teeb seda andmebaasimootor meie eest ning tõenäoliselt saab selleks tüübiks BTREE.
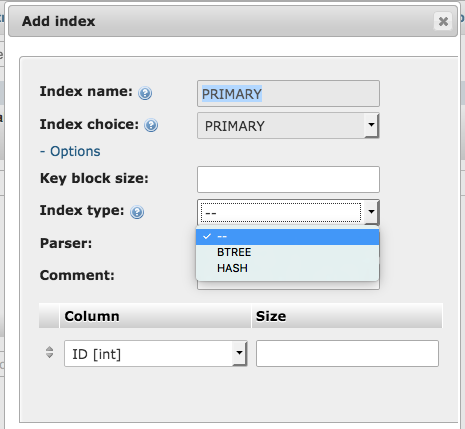
Indeksi muutmine
Kui meil on tabel juba varasemalt defineeritud, siis olemasolevaid indekseid näeme tabeli struktuuri lehel

Siit on näha, et meie tabelil ongi ainult üks PRIMARY tüüpi indeks. Aga kui me soovime teostada otsinguid samas tabelis olevate väljade Eesnimi ja Perenimi alusel, siis tuleks ka nendele väljadele indeks luua. Siin näites eeldame, et teeme oma päringud alati sellisel viisil, et päringu tingimustes määrame kõigepealt Eesnimi ja seejärel Perenimi väärtuse:
SELECT * FROM testtabel WHERE Eesnimi='Mari' AND Perenimi='Maasikas'
Või siis sorteerime samal viisil:
SELECT * FROM testtabel ORDER BY Eesnimi, Perenimi
Siin on meil valida, et kas teha kaks erinevat indeksit, kus üks indeks on Eesnime välja kohta ja teine Perenime välja kohta, kuid kuna päringutest on näha, et kasutame neid välju alati koos, siis on mõistlik teha hoopis ühine indeks.
Selle jaoks märgime ära need väljad, mida tahame koos indeksisse panna ja klikime lingil “Index”
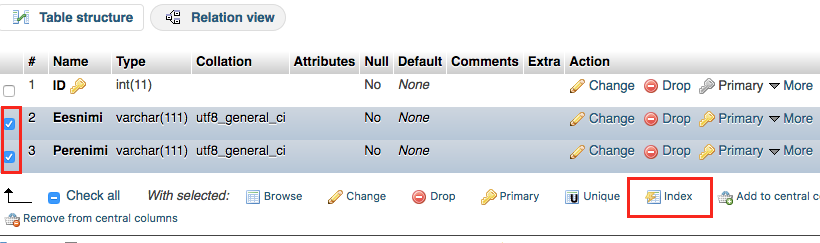
Tulemuseks on siis täiendav indeks, mis katab ära mitu välja.
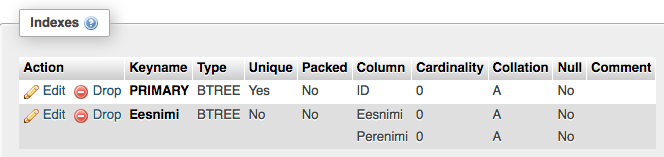
Indeksite valimine
Kuidas me aga saame teada, et milliseid indekseid üldse kasutada? Eespool sai mainitud, et lausindekseerimine võib kasu asemel hoopis kahju teha (andmete lisamine/muutmine/kustutamine võib muutuda aeglasemaks), seega peame suutma kuidagi otsustada, et milliseid indekseid on meile vaja.
Kõige esimene tegevus oleks vaadata üle oma SQL laused. Lihtsama lause puhul on silmaga näha, et milliseid indekseid oleks tarvis. Need väljad, mida kasutame WHERE ning ORDER BY tingimustes peakski olema indekseeritud.
SELECT * FROM kliendid WHERE joined > '2001-01-01' AND name LIKE '%test%'
Siin oleks meil lisaks PRIMARY võtmele vaja seada indeksid väljadele joined (välja tüüp peaks olema kas TIMESTAMP vmt. ajaväli) ja name (välja tüüp peaks olema VARCHAR).
Kui aga meil on aga tegemist juba keerukama päringuga, näiteks kasutame erinevaid JOINE jmt. siis puhtalt silmaga pilgu heitmisest ei pruugi piisata. Sellisel juhul on tarvis juba kasutada abistavaid tööriistu, milleks SQL kontekstis on eelkõige märksõna EXPLAIN. Nimelt kui lisame selle märksõna suvalise päringu ette, siis andmebaas mitte ei teosta seda päringut, vaid analüüsib selle päringu efektiivsust ja tagastab oma analüüsi tulemuse.
EXPLAIN SELECT * FROM testtabel
WHERE Eesnimi='Mari' AND Perenimi='Maasikas'
Ilma eelpool defineeritud Eesnimi ja Perenimi indeksita on analüüsi tulemus järgmine:
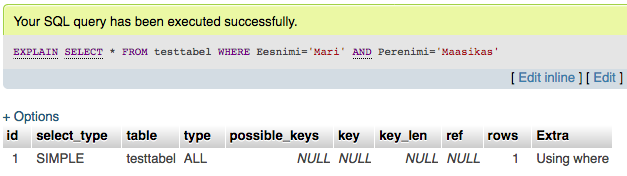
- select_type on SIMPLE. See tähendab, et päring ei tee alampäringuid ega JOINe. Meie puhul on see OK, see lihtsalt ütleb, et tegu on lihtsat tüüpi päringuga
- table on testtabel ehk siis tabel, mille pihta päringut teeme
- type on ALL mis tähendab, et tulemuste leidmiseks peab andmebaasimootor läbi vaatama kõik tabelis olevad kirjed. See on kõige halvem väärtus üldse ja sellega tuleks meil kindlasti tegeleda. Palju parem variant oleks näha siin const väärtust, mis tähendaks täpset ja ainsat indeksivastet.
- possible_keys on NULL, mis tähendab, et andmebaasimootor ei suutnud tuvastada ühtegi kasutatavat indeksit selle päringu teostamiseks. Tegelikult tahaks me siin näha viiteid indeksite juurde.
- key on NULL, siin peaks näha olema siis konkreetne indeksi nimetus, mida päringu teostamisel kasutati. Kuna ühtegi indeksi ei leitud, ei saanud ka midagi neist kasutada
- key_len näitab valitud indeksi mälukasutust. Kuna indeksi ei leitud, on see väärtus NULL
- ref näitab väärtusi, mida kasutatakse indeksiga võrdlemisel. Siin on see muidug jälle NULL
- rows näitab kirjete arvu, mida tuli tulemuse leidmiseks läbi vaadata. Selles tabelis on ainult üks rida ja seega ongi selleks väärtuseks 1. Mida suurem see number on, seda halvem meie jaoks ning siit tulebki kodulehe “aeglaseks muutumine”. Ühe rea läbi vaatamine on ka indeksi puudumisel väga kiire, aga mida rohkem ridu aja jooksul lisandub ning mida rohkem ridu on vaja iga päringu jooksul läbi vaadata, seda kauem võtab iga päring edaspidi aega.
Proovime nüüd sama päringut eelpool loodud indeksiga, kus meil on mitme välja indeks nimega Nimeindeks, mis sisaldab endas Eesnime ja Perenime välju.
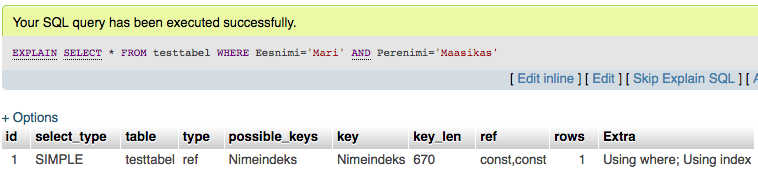
Kõik olulised kohad on nüüd korras
- type on ref ehk oodatud tüüp = operatsiooni korral
- possible_keys on Nimeindeks ehk et leiti vähemalt üks sobiv indeks
- key on Nimeindeks ehk et andmebaas otsustas kasutada saadaolevat indeksi (alati ei pruugi, näiteks juhul kui indeksi lugemine on kirjete niisama läbi vaatamisest suurem vaev)
- ref on const,const ehk et andmeid võrreldi kahe konstantse väärtuse vastu
Lõppsõna
Kodulehe kiirendamiseks peaksime EXPLAIN käsuga üle vaatama ka kõik oma muud päringud. Kusjuures mõnikord võib olla, et mõistlikum on teha ümber päringu lause, mitte indeks. Seda siis juhul kui tegelikult oleks sobiv indeks olemas, kuid miskipärast ei lähe see meie päringulausega kokku. Topelt indekseid teha (eelkõige kehtib see siis mitme välja indeksite puhul), mis on üksteisega väga sarnased, ei ole ka eriti mõtet.
Lisaks tasuks üle vaadata ka MySQL või MariaDB dokumentatsioonist üldised juhendid päringute optimeerimise jaoks.
Populaarsed postitused

CloudFest 2024: AI annab riistvarale uue hingamise

Zone+ WordPressi Assistent: kuidas AI abiga sekunditega veebileht luua

Aegunud PHP on aegunud PHP
